CREAT
注意:数据类型varchar和char的区别,尽量别使用char类型。
-- 创建数据库
CREATE DATABASE duchaoqun;
-- 创建一个表
CREATE TABLE "tb_001" (email varchar(100), nickname varchar(50),password varchar(32));
-- 自增字段,默认值,主键
CREATE TABLE
tb_person
(
id serial, -- 自增的字段
timestamp timestamp default now(), -- 使用默认值
PRIMARY KEY (id) -- 指定主键
);如果不存在, 创建表;
create table if not exists table_410
(
id int8,
name varchar(50),
risk_text text
);- 如果一个数学表达式中包含一个空值,那么该数学表达式的结果为空值。
-- 可以直接在(数值)字段上使用运算符。
select t1.col1 + 1 from t1;
-- 使用AS关键字设置别名,如果别名中有特殊字符,需要使用双引号。
select t1.col1 + 1 AS res FROM t1;
-- 使用distinct来消除重复的行。
select distinct col1 from t1; 验证查询语句
SELECT 1 FROM dual; -- Oracle 独有的 dual 表。
SELECT 1; -- PostgreSQL
SELECT 1 FROM INFORMATION_SCHEMA.SYSTEM_USERS; -- hsqldb
SELECT 1 FROM sysibm.sysdummy1 -- DB2
SELECT 1 -- MySql
SELECT 1 -- Microsoft SQL Server
SELECT 1 -- ingres
SELECT 1 -- H2
values 1 -- derby
SELECT 1 FROM rdb$database -- FirebirdLIMIT 使用 case when 表达式
select
case
when age < 18 then 'A'
when age >= 18 and age < 25 then 'B'
when age >= 25 and age < 36 then 'C'
when age >= 36 and age < 50 then 'D'
when age >= 50 then 'E'
end area,
count(*) count
from
(select round((CURRENT_DATE - birthday)/365) as age from contact) as birthday
group by area;拼接字段或者字符
SELECT country.c_name || country.e_name FROM public.country;
SELECT country.c_name || ' - 国家' FROM public.country;
SELECT concat(country.c_name, ' - 国家') FROM public.country;FROM
基础
-- 从一个表获取数据
select col1,col2,col3,col4 from table1多表
笛卡尔积:连接条件被忽略,第一个表中所有的行与第二个表中的所有的行连接
-- 从多个表中提取数据,在 WHERE 子句中书写连接条件
select aa.column,bb.column
from table1 aa,table2 bb -- 注意使用表的别名简化查询
where aa.column1=bb.column2;
-- Oracle中使用加号,可以用外连接来查出在 table1 表中不匹配连接条件的行
select table1.column,table2.column
from table1 aa,table2 bb
where aa.column1(+)=bb.column2;
-- Informix 中使用 outer 关键字
select table1.column,table2.column
from table1 aa,outer table2 bb
where aa.column1=bb.column2;
-- 一个表使用两个别名,自己关联自己
select table1.column,table2.column
from table1 aa,table1 bb
where aa.column1=bb.column2;WHERE
查询的限定条件
-- 使用运算符
-- 等于:=
-- 大于:>
-- 大于等于:>=
-- 小于等于:<=
-- 不等于:<> or !=
SELECT col1,col2,col3,col4
FROM table1
WHERE col1 = 1;
-- 介于两个值中间的一个条件
WHERE col1 BTEWEEN 1 AND 100;
-- 值在一个列表中
WHERE col1 IN(1,2,3,4,5);
-- 使用 like 的时候需要用“单引号”括起来。
-- %代表0个或者多个字符,_代表1个字符。
WHERE col1 LIKE 'S%';
-- 判断空值
WHERE col1 IS NULL;
WHERE col1 IS NOT NULL;
-- 使用 AND 添加多个条件必须都为真
WHERE col1 IN(1,2,3,4,5) AND col2 IS NULL;
-- 使用 OR 添加多个条件其中一个为真即可
WHERE col1 IN(1,2,3,4,5) OR col2 IS NULL;WHERE后面的条件顺序影响
WHERE子句后面的条件顺序对大数据量表的查询会产生直接的影响,
如
Select * from zl_yhjbqk where dy_dj = ‘1K以下’ and xh_bz=1
Select * from zl_yhjbqk where xh_bz=1 and dy_dj = ‘1K以下’
以上两个SQL中dy_dj及xh_bz两个字段都没进行索引,所以执行的时候都是全表扫描,第一条SQL的dy_dj = ‘1KV以下’条件在记录集内比率为99%,而xh_bz=1的比率只为0.5%,在进行第一条SQL的时候99%条记录都进行dy_dj及xh_bz的比较,而在进行第二条SQL的时候0.5%条记录都进行dy_dj及xh_bz的比较,以此可以得出第二条SQL的CPU占用率明显比第一条低。
INSERT
-- 向表中插入数据
INSERT INTO table_name(id,content) VALUES (1,'AOYE');
-- 从现有的表里面取一些字段,然后插入到新表里面,留意字段顺序。
insert into person1(nickname,birthday,address,nation) select nickname,birthday,address,nation from person;
-- 也可以直接使用常量。
insert into table1 select generate_series(1,10),'aa';
-- 要求目标表Table2不存在,因为在插入时会自动创建表Table2,并将Table1中指定字段数据复制到Table2中。
SELECT column1, column2 into Table2 from Table1ALTER
ALTER DATABASE lms RENAME TO lms_20190315; -- 修改数据库名称
ALTER TABLE table_name RENAME TO new_name; -- 修改表名称
ALTER TABLE table_name RENAME column_name to new_column_name; -- 更改列的名字
ALTER TABLE table_name ADD COLUMN column_name datatype; -- 增加一列
ALTER TABLE table_name ADD COLUMN column_name timestamp default now(); -- 增加一列,指定默认值
ALTER TABLE table_name ADD COLUMN column_name VARCHAR(10) NOT NULL DEFAULT 'Pending'; -- 增加一列,非空,指定默认值。
ALTER TABLE table_name DROP COLUMN column_name; -- 删除一列
ALTER TABLE table_name ALTER COLUMN column_name TYPE datatype; -- 修改列,修改类型
ALTER TABLE table_name ALTER COLUMN column_name TYPE BIGINT USING column_name::BIGINT; -- 修改列,修改类型
-- 修改列,添加默认值
ALTER TABLE table_name ALTER COLUMN column_name SET DEFAULT expression;
ALTER TABLE table_name ALTER COLUMN column_name DROP DEFAULT; -- 修改列,删除默认值
ALTER TABLE table_name ALTER COLUMN column_name DROP SET NOT NULL; -- 修改列,添加非空约束
ALTER TABLE table_name ALTER COLUMN column_name DROP NOT NULL; -- 修改列,删除非空约束
-- 添加外键约束(modify_by_id此表字段,login_user(id)外表字段)
alter table vehicle add foreign key(modify_by_id) references login_user(id);
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(id); -- 添加唯一约束
ALTER TABLE table_name DROP CONSTRAINT constraint_name; -- 删除约束psql -d template1 -c “ALTER USER postgres WITH PASSWORD ‘K1ebfBfa2078A5cD’;” — 修改用户密码
DROP
删除所有的表,保存库实例。
drop schema public cascade;
create schema public;
DROP TABLE table_001; — 删除一个表
DROP DATABASE zabbix; — 删除数据库
DROP USER zabbix; — 删除一个用户
DROP TABLE “public”.“temp2” — 删除一个表
DROP INDEX fk5toqqq5xiay8n20o7t4padopm ON tablename; — 删除索引
ALTER TABLE workflow_stage DROP CONSTRAINT fkfxat959huepdg76r1dw28uhbh; — 删除外键
DROP TABLE products CASCADE; —会删除所有的依赖关系
—
GROUP BY
在 SELECT 语句中,没有使用分组函数的列,必须出现在 GROUP BY 子句中。
GROUP BY 子句中的列可以不出现在 SELECT 语句中。
根据多个列进行分组,GROUP BY 紧跟多个列名,先按第一个分组,在第一个基础上进行第二个分组。
不能在 WHERE 子句中对分组列做出限定,需要使用 HAVING 子句来限定分组,然后再使用 ORDER BY 语句。
-- 再使用分组函数的时候,需要按照字段进行分组查询
SELECT COUNT(*) FROM t1 GROUP BY column1;
-- 使用 HAVING 限定分组,相当于另外一层 WHERE 语句。
SELECT COUNT(column1) as count1 FROM t1 GROUP BY column1 HAVING COUNT(column1) > 2;
PG中,having 字句不能使用别名。
LIMIT
限定查询返回结果的条数。
— LIMIT 子句的 SELECT 语句基本语法:PostgreSQL 放在语句最后面。
select col1, col2, col3
from t1
limit [no of rows]
LIMIT 子句使用OFFSET 的 SELECT 语句基本语法:
select column1, column2, column3
from table_name
limit [no of rows] offset [row num]
LIKE
Like用法:_ 匹配一个字符,% 匹配0个或者多个字符,[0-9] 匹配0至9中的一个字符,
注意:Or运算符的优先级高于and
Order by ASC是升序 order by DESC是降序
函数sum(),max(),min(),count(),
Having 子句对分组的结果进行过滤,相当于分组的where条件
DELETE
DELETE FROM PUBLIC.LOGIN_USER WHERE LOGIN_USER.ID = 4698UPDATE
-- 将某个字段中的一些字符替换成另外一些字符(将class字段中的cindata字符替换成next字符)。
update area set class=replace(class,'cindata','next') where area_id = 587
-- 用一个表的数据去更新另外一个表的数据
UPDATE
data_provider_interface_strategy
SET
data_provider_interface_id =
( SELECT
id
FROM
data_provider_interface
WHERE
data_provider_interface_strategy.name = data_provider_interface.name );
-- 更新一列,注意B表的字段名,可以使用别名对应
update table1 A set (column1) =
(select column1 from table2 B where a.relColumn = b.relColumn );
-- 更新多列
UPDATE TABLE a SET ( column01, colum02, column03 ) =
( SELECT b.column01, b.column02, b.column03 FROM table2 b
WHERE a.relColumn = b.relColumn)
常用函数
AVG(column) — 对结果列求平均
CONCAT(‘Str1’,‘Str2’) — 拼接两个字符串 == ‘Str1’||‘Str2’
COALESCE(column,0.00) — 如果是 null 则使用后面的数值。
COALESCE(column,0.00)::NUMERIC — 如果是 null 则使用后面的数值,转换成 NUMERIC 类型。
INITCAP(‘PostgreSQL’) — 首字母大写
LOWER(‘PostgreSQL’) — 转换小写
MAX(column) — 结果比较取最大值
MIN(column) — 结果比较取最小值
MOD(1000,300) — 出发计算余数
ROUND(column,2) — 四舍五入,保留小数点右侧两位
ROUND(column,-2) — 四舍五入,保留小数点左侧两位
SUM(column) — 对结果求和
UPPER(‘PostgreSQL’) — 转换大写
regexp_matches PG
正则匹配,三个参数,第一个是待匹配的字段,第二个是正则,第三个i是不区分大小写,或者是g参数
select serial_number,regexp_matches(serial_number, ’([\d]+)号’,‘i’) from public.contract;
吉高担保履函〔2020〕005号 {“005”}
返回的是数组:可以用如下两个方式来取出数组内容
select serial_number,(regexp_matches(serial_number, ’([\d]+)号’,‘i’))[1] from public.contract;
select serial_number,array_to_string(regexp_matches(serial_number, ’([\d]+)号’,‘i’),’;’) from public.contract;
ROUND与类型转换
ROUND((fs.balance_amount / aa.balance_amount)::NUMERIC,2) AS liu_dong_bi_lv
LIMIT
返回特定数量的行,PG中将关键字放在语句最后面。
SELECT
fs.finance_date_year,
FROM
finance_sheet AS fs
LIMIT
3
PG操作时间
select to_char((SELECT now()::timestamp), ‘yyyy’); — 当前年
select to_char((SELECT now()::timestamp+ ‘-1 year’),‘yyyy’); — 去年
select to_char((SELECT now()::timestamp+ ‘1 year’),‘yyyy’); — 明年
四则运算
-- 除法运算,使用 / 会舍去小数部分,使用round函数来指定精度。
select 10/3 as col_1;
select round(numeric '10' / numeric '3', 2) as col_1;
select round(10==numeric/3==numeric, 2) as col_1;
select round(cast('10' as numeric) / cast ('3' as numeric), 2) as col_1;类型转换
SELECT numeric '10' / numeric '3' AS col_1; -- PG语法
SELECT '10'==numeric/'3'==numeric AS col_1; -- PG语法
SELECT CURRENT_DATE::varchar(20); -- PG语法
select cast('10' as numeric) / cast ('3' as numeric) as col_1; -- 标准的SQL语法
-- cast 函数
select substring(cast('12345' as text), 3, 1);case when
在Select语句中的语法:
SELECT =
CASE
WHEN THEN
WHEN THEN
ELSE
END
样例:
SELECT
CASE MONTH(SYSDATE())
WHEN 1
THEN “1111”
WHEN 2
THEN “2222”
ELSE “000”
END AS “Test”
FROM
DUAL
SELECT
Title,
‘Price Range’ =
CASE
WHEN price IS NULL THEN ‘Unpriced’
WHEN price < 10 THEN ‘Bargain’
WHEN price BETWEEN 10 and 20 THEN ‘Average’
ELSE ‘Gift to impress relatives’
END
FROM titles
ORDER BY price
在GROUP BY子句中的用法:
SELECT ‘Number of Titles’, Count(*)
FROM titles
GROUP BY
CASE
WHEN price IS NULL THEN ‘Unpriced’
WHEN price < 10 THEN ‘Bargain’
WHEN price BETWEEN 10 and 20 THEN ‘Average’
ELSE ‘Gift to impress relatives’
END
你甚至还可以组合这些选项,添加一个 ORDER BY 子句,如下所示:
SELECT
CASE
WHEN price IS NULL THEN ‘Unpriced’
WHEN price < 10 THEN ‘Bargain’
WHEN price BETWEEN 10 and 20 THEN ‘Average’
ELSE ‘Gift to impress relatives’
END AS Range,
Title
FROM titles
GROUP BY
CASE
WHEN price IS NULL THEN ‘Unpriced’
WHEN price < 10 THEN ‘Bargain’
WHEN price BETWEEN 10 and 20 THEN ‘Average’
ELSE ‘Gift to impress relatives’
END,
Title
ORDER BY
CASE
WHEN price IS NULL THEN ‘Unpriced’
WHEN price < 10 THEN ‘Bargain’
WHEN price BETWEEN 10 and 20 THEN ‘Average’
ELSE ‘Gift to impress relatives’
END,
Title
注1:为了在 GROUP BY 块中使用 CASE,查询语句需要在 GROUP BY 块中重复 SELECT 块中的 CASE 块。
在UPDATE子句中的用法:
工资5000以上的职员,工资减少10%
工资在2000到4600之间的职员,工资增加15%
很容易考虑的是选择执行两次UPDATE语句,如下所示
—条件1
UPDATE Personnel
SET salary = salary * 0.9
WHERE salary >= 5000;
—条件2
UPDATE Personnel
SET salary = salary * 1.15
WHERE salary >= 2000 AND salary < 4600;
但是事情没有想象得那么简单,假设有个人工资5000块。首先,按照条件1,工资减少10%,变成工资4500。接下来运行第二个SQL时候,因为这个人的工资是4500在2000到4600的范围之内,需增加15%,最后这个人的工资结果是5175,不但没有减少,反而增加了。如果要是反过来执行,那么工资4600的人相反会变成减少工资。暂且不管这个规章是多么荒诞,如果想要一个SQL 语句实现这个功能的话,我们需要用到Case函数。代码如下:
UPDATE
Personnel
SET
salary =
CASE
WHEN salary >= 5000
THEN salary * 0.9
WHEN salary >= 2000
AND salary < 4600
THEN salary * 1.15
ELSE salary
END;
注1:最后一行的ELSE salary是必需的,要是没有这行,不符合这两个条件的人的工资将会被写成NUll。
注2:在Case函数中Else部分的默认值是NULL
实例:两个表数据是否一致的检查
Case函数不同于DECODE函数。在Case函数中,可以使用BETWEEN,LIKE,IS NULL,IN,EXISTS等等。比如说使用IN,EXISTS,可以进行子查询,从而实现更多的功能。
下面具个例子来说明,有两个表,tbl_A,tbl_B,两个表中都有keyCol列。现在我们对两个表进行比较,tbl_A中的keyCol列的数据如果在tbl_B的keyCol列的数据中可以找到, 返回结果’Matched’,如果没有找到,返回结果’Unmatched’。
要实现下面这个功能,可以使用下面两条语句
—使用IN的时候
SELECT
keyCol,
CASE
WHEN keyCol IN
(
SELECT
keyCol
FROM
tbl_B )
THEN ‘Matched’
ELSE ‘Unmatched’
END Label
FROM
tbl_A;
—使用EXISTS的时候
SELECT
keyCol,
CASE
WHEN EXISTS
(
SELECT
*
FROM
tbl_B
WHERE
tbl_A.keyCol = tbl_B.keyCol )
THEN ‘Matched’
ELSE ‘Unmatched’
END Label
FROM
tbl_A;
注:使用IN和EXISTS的结果是相同的。也可以使用NOT IN和NOT EXISTS,但是这个时候要注意NULL的情况。
实例:在Case函数中使用合计函数
通过在Case函数中嵌套Case函数,在合计函数中使用Case函数等方法,我们可以轻松的解决这个问题。使用Case函数给我们带来了更大的自由度。
最后提醒一下使用Case函数的新手注意不要犯下面的错误
CASE col_1
WHEN 1 THEN ‘Right’
WHEN NULL THEN ‘Wrong’
END
在这个语句中When Null这一行总是返回unknown,所以永远不会出现Wrong的情况。因为这句可以替换成WHEN col_1 = NULL,这是一个错误的用法,这个时候我们应该选择用WHEN col_1 IS NULL。
right
PostgreSQL, returns the last n characters in a string.
select right(serial_number, 3) from opportunity o ;ORDER BY
对结果集进行排序 — DESC降序排列,ASC升序排列 — 按照多个列排序的时候 ORDER BY 后面跟着的列的顺序就是排序的顺序,先按第一列排序,在第一列基础上进行第二列的排序。
WHERE col1 IS NULL
ORDER BY col1 DESCHAVING
PG 中,having关键字不能使用别名,必须使用原来的聚合函数。
truncate
SQLite 中不支持 truncate 语句,只能使用delete来删除全表记录。
CONSTRAINT
关于约束的一些记录。 非主键字段被设置成外键的时候提示:[Code: , SQL State: 42830] ERROR: there is no unique constraint matching given keys for referenced table “t1”
-- 创建 author 表
create table author (id INTEGER, name char(255));
-- 唯一主键才能被添加成外键。
alter table author add primary key(id);
-- 创建 book 表
create table book (id INTEGER, author_id INTEGER, name char(255));
-- 第一,可以直接删除 Book 表记录,Author 表数据不会受到影响。
-- 第二,删除 Author 表记录,串联删除 Book 表数据。
alter table book add foreign key(author_id) references author(id) on delete cascade;
-- 删除约束
alter table book drop constraint 'book_author_id_fkey';Restrict 禁止删除被引用的行 (不能将约束检查推迟到事物的晚些时候)
No Action 如果存在任何引用行,则抛出错误,如果不声明任何行为则No Action就是缺省行为 (允许约束检查推迟到事物的晚些时候)
Cascade 在删除一个被引用的行时,引用他的行被自动删除
Set Null (外键上才有) 删除被引用行时,引用他的字段设置为NULL
Set Default (外键上才有) 删除被引用行时,引用他的字段被设置为缺省值
注意:一个动作声明为Set Default 但是默认值并不能满足外键,那么动作就会失败
JOIN
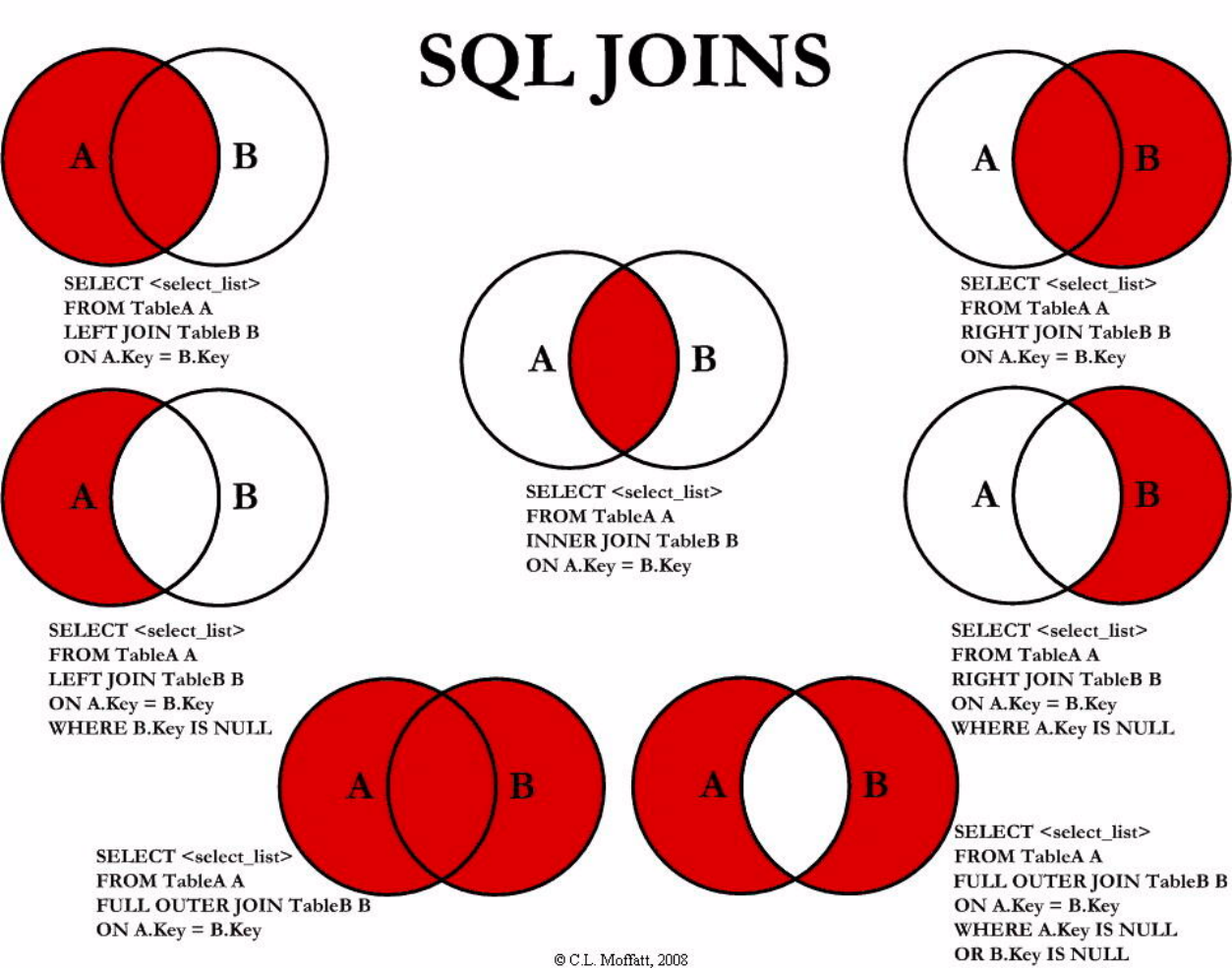
LEFT JOIN
两个表有数值相等的两个字段,关联两个字段,返回左表的所有内容。
select col4,col5
from
(select col1,col2,col3,col4 from table1) table1
left join
(select col1,col2,col3,col5 from table2) table2
-- 第一种使用 on 关联多个相等字段,结果会出现多个相同的列。
on table1.col1 = table2.col1 ...
-- 第二种使用 using 关联多个相等的字段,结果相同的列只保留一个。
using(col1,col2,col3)INNER JOIN
文氏图 Venn diagrams 解释了SQL的Join。 假设我们有两张表。 Table A 是左边的表。 Table B 是右边的表。 其各有四条记录,其中有两条记录name是相同的,如下所示:让我们看看不同JOIN的不同

INNER JOIN
SELECT * FROM TableA
INNER JOIN TableB ON TableA.name = TableB.name
FULL [OUTER] JOIN
SELECT * FROM TableA
FULL OUTER JOIN TableB ON TableA.name = TableB.name

RIGHT [OUTER] JOIN
RIGHT OUTERJOIN 是后面的表为基础,与LEFT OUTER JOIN用法类似。
UNION 与 UNION ALL
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。UNION 只选取记录,而UNION ALL会列出所有记录。
(1)SELECT name FROM TableA UNION SELECT name FROM TableB

选取不同值
(2)SELECT name FROM TableA UNION ALL SELECT name FROM TableB

全部列出来
(3)注意:
SELECT * FROM TableA UNION SELECT * FROM TableB

由于 id 1 Pirate 与 id 2 Pirate 并不相同,不合并
还需要注册的是我们还有一个是“交差集” cross join, 这种Join没有办法用文式图表示,因为其就是把表A和表B的数据进行一个N*M的组合,即笛卡尔积。
表达式如下:SELECT * FROM TableA CROSS JOIN TableB
这个笛卡尔乘积会产生 4 x 4 = 16 条记录,一般来说,我们很少用到这个语法。但是我们得小心,如果不是使用嵌套的select语句,一般系统都会产生笛卡尔乘积然再做过滤。这是对于性能来说是非常危险的,尤其是表很大的时候。